

 UNP Education
UNP Education- 12 Sep, 2024
- 0 Comments
- 5 Mins Read
August 2024 Step-by-Step Guide to Building Machine Learning Models with Python
Machine learning (ML) is a powerful tool that allows computers to learn from data and make predictions or decisions without being explicitly programmed. Python, with its rich libraries and ease of use, is one of the most popular languages for building ML models. This guide will walk you through the steps to create a machine learning model using Python, from data collection to model evaluation.
1. Setting Up the Environment
Before starting, ensure that you have Python installed on your system. The best way to work with ML in Python is by using a virtual environment. This helps to manage dependencies and avoid conflicts.
- Install Python: Download and install Python from the official website.
- Set up a virtual environment: In your terminal, create a virtual environment by running
python -m venv ml_env. - Activate the virtual environment:
- On Windows:
ml_env\Scripts\activate - On macOS/Linux:
source ml_env/bin/activate
- On Windows:
- Install necessary libraries: Install essential libraries such as NumPy, Pandas, Scikit-learn, and Matplotlib using the command:
pip install numpy pandas scikit-learn matplotlib
Ready to take you Data Science and Machine Learning skills to the next level? Check out our comprehensive Mastering Data Science and ML with Python course.

2. Collecting and Preparing Data
The first step in any machine learning project is to gather the data you’ll use to train your model. Data can come from various sources, such as CSV files, databases, or APIs.
Load data: Use Pandas to load your dataset into a DataFrame:
Feature selection and engineering: Choose the relevant features for your model and create new ones if necessary. This step can significantly impact the model’s performance.
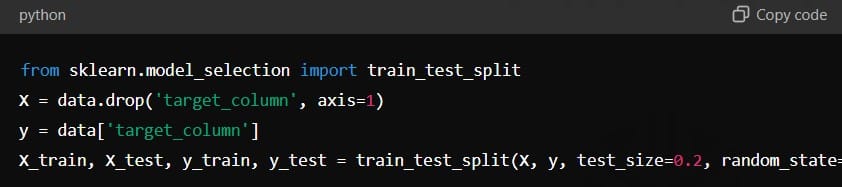
Split the data: Divide the dataset into a training set and a test set to evaluate your model’s performance later:



3. Choosing a Model
Different machine learning algorithms are suited to different types of problems. Some common algorithms include:
- Linear Regression: For predicting a continuous target variable.
- Logistic Regression: For binary classification tasks.
- Decision Trees: For both classification and regression tasks.
- Support Vector Machines (SVM): For classification tasks.
- Random Forests: For complex classification tasks with a large amount of data.
Select the appropriate algorithm based on your problem. Here’s an example using a Decision Tree for a classification task:

4. Training the Model
Training is the process where the model learns the patterns in the data by adjusting its parameters.

After training, the model will have learned the relationships in the training data and can be used to make predictions.

Ready to take you Data Science and Machine Learning skills to the next level? Check out our comprehensive Mastering Data Science and ML with Python course.
Add Your Heading Text Here
5. Evaluating the Model
It’s crucial to assess how well your model performs on unseen data. This is done by evaluating the model on the test set.
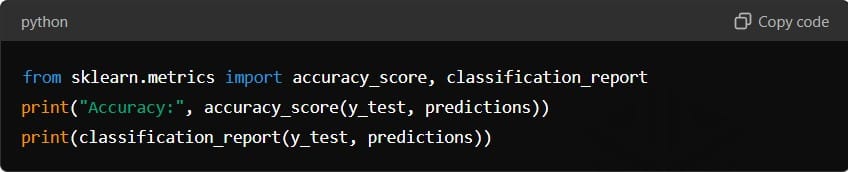
Make predictions:

Measure accuracy: Accuracy is a common metric, but others such as precision, recall, and F1-score are also important, especially in classification tasks:
Confusion Matrix: For classification tasks, a confusion matrix can help visualize the performance:

6. Fine-Tuning the Model
Often, the initial model is not the best one. Fine-tuning can involve:
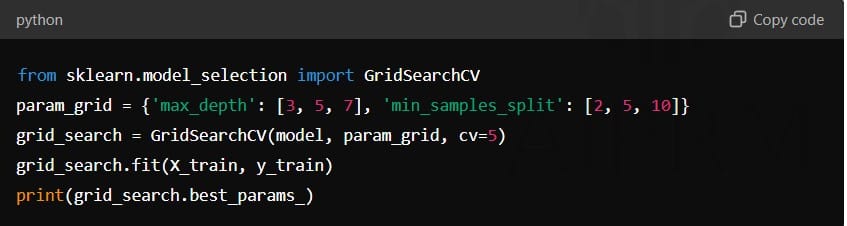
Hyperparameter tuning: Use techniques like Grid Search or Random Search to find the best parameters for your model.
Cross-validation: This helps in assessing how the model performs across different subsets of the data:
7. Deploying the Model
Once satisfied with the model’s performance, it can be deployed into a production environment where it can make predictions on new data. This step often involves saving the model and integrating it into an application.
Save the model:

Save the model:

Conclusion
Building a machine learning model with Python involves several critical steps, from setting up the environment to deploying the model. Each stage requires careful consideration, from data preparation to model evaluation and fine-tuning. With the right approach, Python makes it relatively easy to develop powerful ML models that can drive insights and add value to various applications.
Ready to take you Data Science and Machine Learning skills to the next level? Check out our comprehensive Mastering Data Science and ML with Python course.
Frequently Asked Questions (FAQ) - for Building Machine Learning Models with Python
1. What is a machine learning model?
A machine learning model is a program that is trained to recognize patterns and make predictions or decisions based on data. It learns from the data provided and can apply this knowledge to new, unseen data.
2. Why is Python commonly used for machine learning?
Python is widely used for machine learning due to its simplicity, extensive libraries (like Scikit-learn, Pandas, and NumPy), and strong community support. These features make Python an excellent choice for both beginners and experienced developers.
3. What are the essential Python libraries for machine learning?
Key Python libraries for machine learning include:
- NumPy: For numerical computations.
- Pandas: For data manipulation and analysis.
- Scikit-learn: For building and evaluating machine learning models.
- Matplotlib/Seaborn: For data visualization.
4. How do I handle missing data in my dataset?
Missing data can be handled by:
- Removing rows/columns: If the missing data is minimal.
- Imputation: Filling in missing values with mean, median, or mode.
- Using algorithms that handle missing data: Some machine learning algorithms can handle missing data naturally.
5. What is the purpose of splitting data into training and test sets?
Splitting data into training and test sets helps evaluate the model’s performance on unseen data. The training set is used to train the model, while the test set is used to assess how well the model generalizes to new data.
6. How do I choose the right machine learning algorithm?
Choosing the right algorithm depends on the problem you’re solving:
- Regression tasks: Linear Regression, Decision Trees.
- Classification tasks: Logistic Regression, SVM, Random Forest.
- Clustering tasks: K-Means, Hierarchical Clustering. Consider the data size, problem complexity, and the need for interpretability.
Ready to take you Data Science and Machine Learning skills to the next level? Check out our comprehensive Mastering Data Science and ML with Python course.